We present All-Pairs Multi-Field Transforms (AMT), a new network architecture for video frame interpolation. It is based on two essential designs. First, we build bidirectional correlation volumes for all pairs of pixels, and use the predicted bilateral flows to retrieve correlations for updating both flows and the interpolated content feature. Second, we derive multiple groups of fine-grained flow fields from one pair of updated coarse flows for performing backward warping on the input frames separately. Combining these two designs enables us to generate promising task-oriented flows and reduce the difficulties in modeling large motions and handling occluded areas during frame interpolation. These qualities promote our model to achieve state-of-the-art performance on various benchmarks with high efficiency. Moreover, our convolution-based model competes favorably compared to Transformer-based models in terms of accuracy and efficiency.
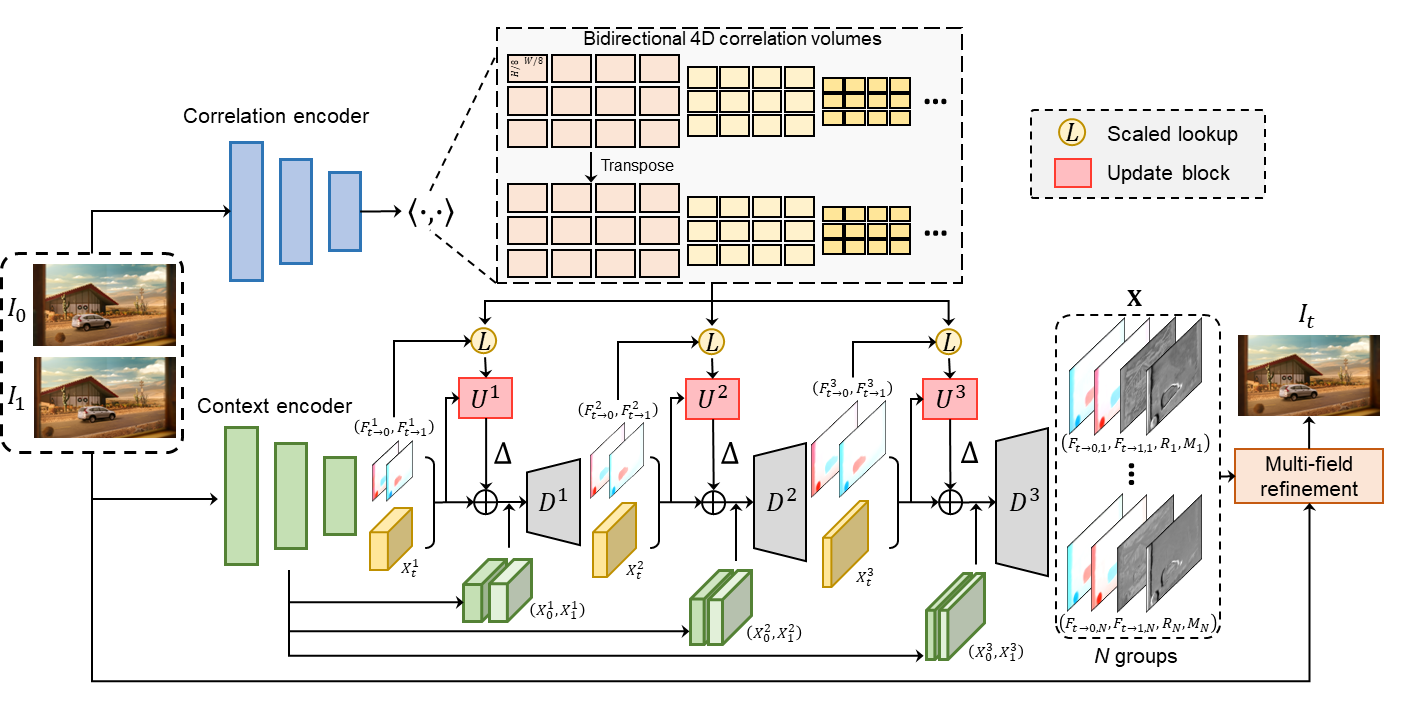
Architecture overview of the proposed AMT. Firstly, the input frames are sent to the correlation encoder to extract features, which are used to construct bidirectional correlation volumes. Then, the context encoder extracts pyramid features of visible frames and generates initial bilateral flows and interpolated intermediate feature. Next, we use bilateral flows to retrieve bidirectional correlations for jointly updating flow fields and the intermediate feature at each level. Finally, we generate multiple groups of flow fields, occlusion masks, and residuals based on the coarse estimate for interpolating the intermediate frame.
@inproceedings{licvpr23amt,
title={AMT: All-Pairs Multi-Field Transforms for Efficient Frame Interpolation},
author={Li, Zhen and Zhu, Zuo-Liang and Han, Ling-Hao and Hou, Qibin and Guo, Chun-Le and Cheng, Ming-Ming},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023}
}
For technical questions, please contact zhenli1031[AT]gmail.com and nkuzhuzl[AT]gmail.com. For commercial licensing, please contact cmm[AT]nankai.edu.cn.
This work is funded by the National Key Research and Development Program of China (NO.2018AAA0100400), Fundamental Research Funds for the Central Universities (Nankai University, NO.63223050), China Postdoctoral Science Foundation (NO.2021M701780).

